PE FIle Format: DOS Header, DOS Stub, Rich Header
·6 mins
Table of Contents
Introduction #
- In the previous blog post, we introduced the PE file format and we were able to give an overview of the structure of a PE executable.
- In todays blog post, we are going to explore in depth that structure and we will focus on the
DOS Header, DOS StubandRich Header.
Prerequisites #
- Basic C/C++ and Python programming knowledge
- Willingness to learn
DOS Header #
- We had seen that it is a 64 bytes of size structure used for
backward compatibility. The DOS Header makes the file an MS-DOS executable in the sense that when the file is loaded on an MS-DOS, the DOS stub gets executed and produces the messageThis program cannot be run in DOS mode.Without the DOS Header, if you try to load the executable on MS-DOS, it will not be loaded and will just produce a generic error. - The structure can be represented in code as shown below:
typedef struct _IMAGE_DOS_HEADER{
WORD e_magic; //Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER *PIMAGE_DOS_HEADER;
- While the entire structure holds significance for the PE Loader on MS-DOS, Windows Systems prioritize only specific members. We are going to focus on those elements.
1. e_magic: It’s a 2 byte (WORD) known as the magic number. It’s usually fixed at 0x5A4D or MZ in ASCII and acts as a signature which identifies the file as an MS-DOS executable.
2. e_lfanew: This is the last member of the DOS Header structure situated at offset 0x3C and it plays a crucial role in Windows PE loaders. It holds an offset to the start of NT Headers. It tells the loader where to look for file headers.
- Let’s take a quick look at the DOS Header of a sample executable using the
pebeartool.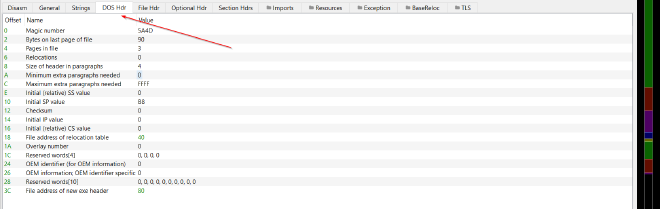
DOS Header of a PE Binary - We can see that the first header member is the magic number, consistently set at the discussed value of 5A4D.
- The last header member, labeled as the
File address of new exe headerat offset 0x3C, is assigned the value 80. By moving to this offset, we find the expected start of the NT headers.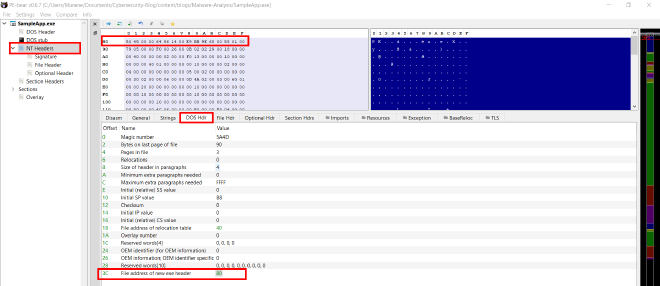
DOS Stub #
- This is the code that runs upon loading the program in MS-DOS. The default error message is “This program cannot be run in DOS mode.” However, users have the option to customize this message during the compilation process.
- That covers everything essential about the DOS stub; we aren’t particularly concerned with it.
Rich Header #
- PE ‘Rich Headers’ were introduced with Visual Studio 97 SP3 release. They lie between the DOS Stub and the start of NT Headers.
- Microsoft did not formally announce the feature or provide documentation for its implementation.
- Original purpose remains unclear, but it seems Microsoft aimed for a development environment fingerprint or aid in diagnostics and debugging.
- Rich Header has proven highly valuable for malware researchers. A few hundred bytes, when interpreted correctly, serve as a strong factor for attribution and detection.
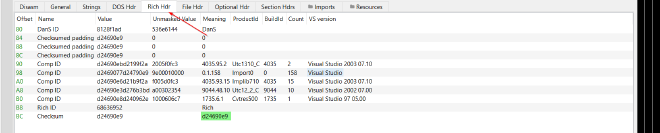
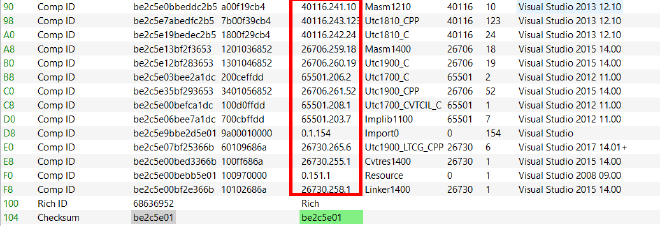
Rich Header of a PE Binary - The rich header consists of a chunk of
XORed datafollowed by a signatureRichand a32 bit checksum valuethat is the XOR Key. - The encrypted data consists of a DWORD Signature
Dans, 3 zeroed-out DWORDs for padding, then pairs of DWORDs each representing an entry.Each entry holds a tool name, its build number and the number of times it has been used. - In each DWORD pair the first pair holds the type ID or the product ID in the high WORD and the build ID in the low WORD, the second pair holds the use count.
- PE-bear parses the Rich Header automatically.
- As an exercise, I wrote a script to parse this header myself, it’s a very simple process, all we need to do is to XOR the data, then read the entry pairs and translate them.
Rich Header Data
45 3F 42 ED 01 5E 2C BE 01 5E 2C BE 01 5E 2C BE
B5 C2 DD BE 0B 5E 2C BE B5 C2 DF BE 7A 5E 2C BE
B5 C2 DE BE 19 5E 2C BE 53 36 2F BF 13 5E 2C BE
53 36 28 BF 12 5E 2C BE DC A1 E2 BE 03 5E 2C BE
53 36 29 BF 35 5E 2C BE DC A1 FC BE 00 5E 2C BE
DC A1 E7 BE 06 5E 2C BE 01 5E 2D BE 9B 5E 2C BE
6B 36 25 BF 07 5E 2C BE 6B 36 D3 BE 00 5E 2C BE
01 5E BB BE 00 5E 2C BE 6B 36 2E BF 00 5E 2C BE
52 69 63 68 01 5E 2C BE
Script
import textwrap
def xordata(data, key):
return bytearray( ((data[i] ^ key[i % len(key)]) for i in range(0, len(data))) )
def rev_endiannes(data):
tmp = [data[i:i+8] for i in range(0, len(data), 8)]
for i in range(len(tmp)):
tmp[i] = "".join(reversed([tmp[i][x:x+2] for x in range(0, len(tmp[i]), 2)]))
return "".join(tmp)
data = bytearray.fromhex("453F42ED015E2CBE015E2CBE015E2CBEB5C2DDBE0B5E2CBEB5C2DFBE7A5E2CBEB5C2DEBE195E2CBE53362FBF135E2CBE533628BF125E2CBEDCA1E2BE035E2CBE533629BF355E2CBEDCA1FCBE005E2CBEDCA1E7BE065E2CBE015E2DBE9B5E2CBE6B3625BF075E2CBE6B36D3BE005E2CBE015EBBBE005E2CBE6B362EBF005E2CBE52696368015E2CBE")
key = bytearray.fromhex("015E2CBE")
rch_hdr = (xor(data,key)).hex()
rch_hdr = textwrap.wrap(rch_hdr, 16)
for i in range(2,len(rch_hdr)):
tmp = textwrap.wrap(rch_hdr[i], 8)
f1 = rev_endiannes(tmp[0])
f2 = rev_endiannes(tmp[1])
print("{} {} : {}.{}.{}".format(f1, f2, str(int(f1[4:],16)), str(int(f1[0:4],16)), str(int(f2,16)) ))
- When we run the script we get output that’s identical to PE-bear’s interpretation, meaning that the script works fine.
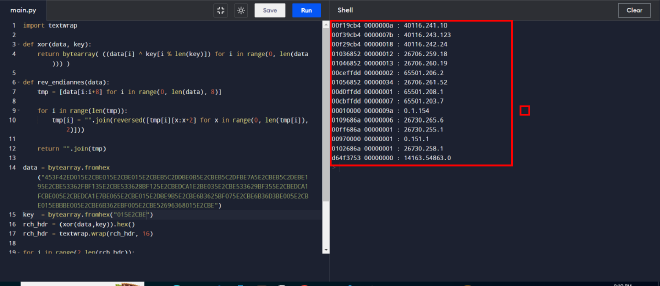
Script Output
- Please note that I had to reverse the byte-order because the data was presented in little-endian.
Conclusion #
- This article covered the initial sections of the PE file, specifically discussing the DOS header and DOS stub.
- We examined the components within the DOS header structure and conducted a reverse analysis of the DOS stub program.
- Additionally, we explored the Rich Header, a structure not inherently integral to the PE file format but deemed worthwhile to investigate.
- See you in the next blog :)