Welcome to my write-up for the E CTF 2025! In this post, I’ll walk through the challenges I tackled, sharing insights into my approach, analysis, and how I cracked the flags. Let’s dive straight into the action!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
At first, this looked like an attempt to alter the text further using XOR. But after tracing the variables, I realized this transformed text string (final_padded_text) was never actually used anywhere.
Note: This doesn't change the functionality of the encryption process, it will run just fine but it just makes it a lot harder to reverse engineer the code.
This made it look like the encryption relied on some kind of structured padding. But after carefully following the code, I realized this padding was never used in the actual encryption process.
Red flag: More junk code to make things appear more complicated.
Once I eliminated all the unnecessary parts of the code, what was left was surprisingly simple.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This was the core encryption logic that was actually responsible for transforming the text. Let’s break it down:
1. Character Conversion: Each character of the text is converted to its ASCII code using ord(char).
2. Shifting: For each character, the code applies a shift that increases with the character’s position. Specifically, it multiplies the character’s index (i + 1) by 3, which means the shift increases as we move through the string. This shifting helps obscure the original text.
Example: The first character gets a shift of 3 ((1 + 1) * 3), the second character gets a shift of 6 ((2 + 1) * 3), and so on.
3. Transformation: After applying the shift, 67 is added to the result. Then, the modulo 256 operation ensures that the result is within the valid range for ASCII characters. The chr() function is used to convert the result back to a character.
This transformation essentially scrambles the original text based on the position of each character, but with a predictable pattern.
To decrypt the encrypted text and retrieve the original data, we need to reverse the steps in the encryption function.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
1. Reverse the Shift: The shift is calculated the same way as in encryption, so we subtract the same amount to reverse it.
2. Subtract the Constant: The 67 that was added during encryption is subtracted here.
3. Apply Modulo 256: To ensure we get the correct ASCII value, we use modulo 256.
We return the decrypted text
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
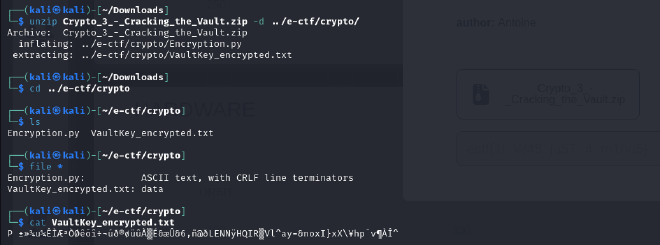
1. Read the encrypted text: We read the entire content of the VaultKey_encrypted.txt and store it in the variable encrypted_text.
2. Decrypting the Encrypted Text: After loading the encrypted content, we pass it through the decryption function that we previously wrote. This function takes the encrypted text, applies the reverse operations, and returns the original plain text.
3. Writing the Decrypted Text to a New File: Once we have the decrypted text, the next step is to save it into a new file, VaultKey_decrypted.txt, so we can review the original data.
4. Finally, we print a message to confirm that the decryption process was successful.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
So, my first move was obvious – take those numbers and convert them into something readable.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The approach here was straightforward: brute force all the possible shifts until something readable came out.
A Caesar cipher works by shifting each letter in the message by a fixed number of positions in the alphabet.
Since there are 26 letters in the alphabet, that means there are only 25 possible shifts (ignoring a shift of 0, which would just be the original text).
I wrote up a quick Python script (but you can use CyberChef) to shift each letter through all 25 possibilities. The goal was to see which shift made sense in the context of the message.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
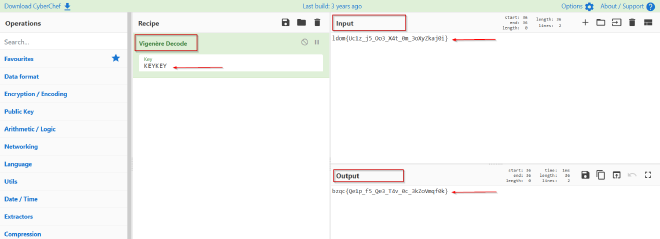
With the key KEYKEY from the Caesar shift, it was time to decrypt the Vigenère cipher. The ciphertext to crack was:
ldom{Uc1z_j5_Oo3_X4t_0m_3oXyZkaj0i}
I could have gone through the manual steps, but why bother when CyberChef has your back? It’s one of my go-to tools for decryption.
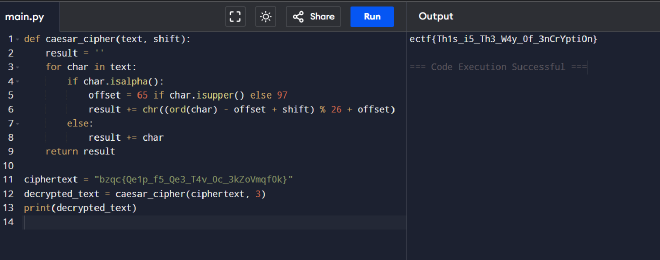
Hit the “Bake” button, I got this: bzqc{Qe1p_f5_Qe3_T4v_0c_3kZoVmqf0k}
The output was still scrambled, but it was definitely progress.
Since the Caesar cipher shift was a known factor, I decided to take that 3 shift and apply it again to tidy things up. You can use CyberChef
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters